Anatoly Zelenin
Debezium: Change Data Capture für Apache Kafka
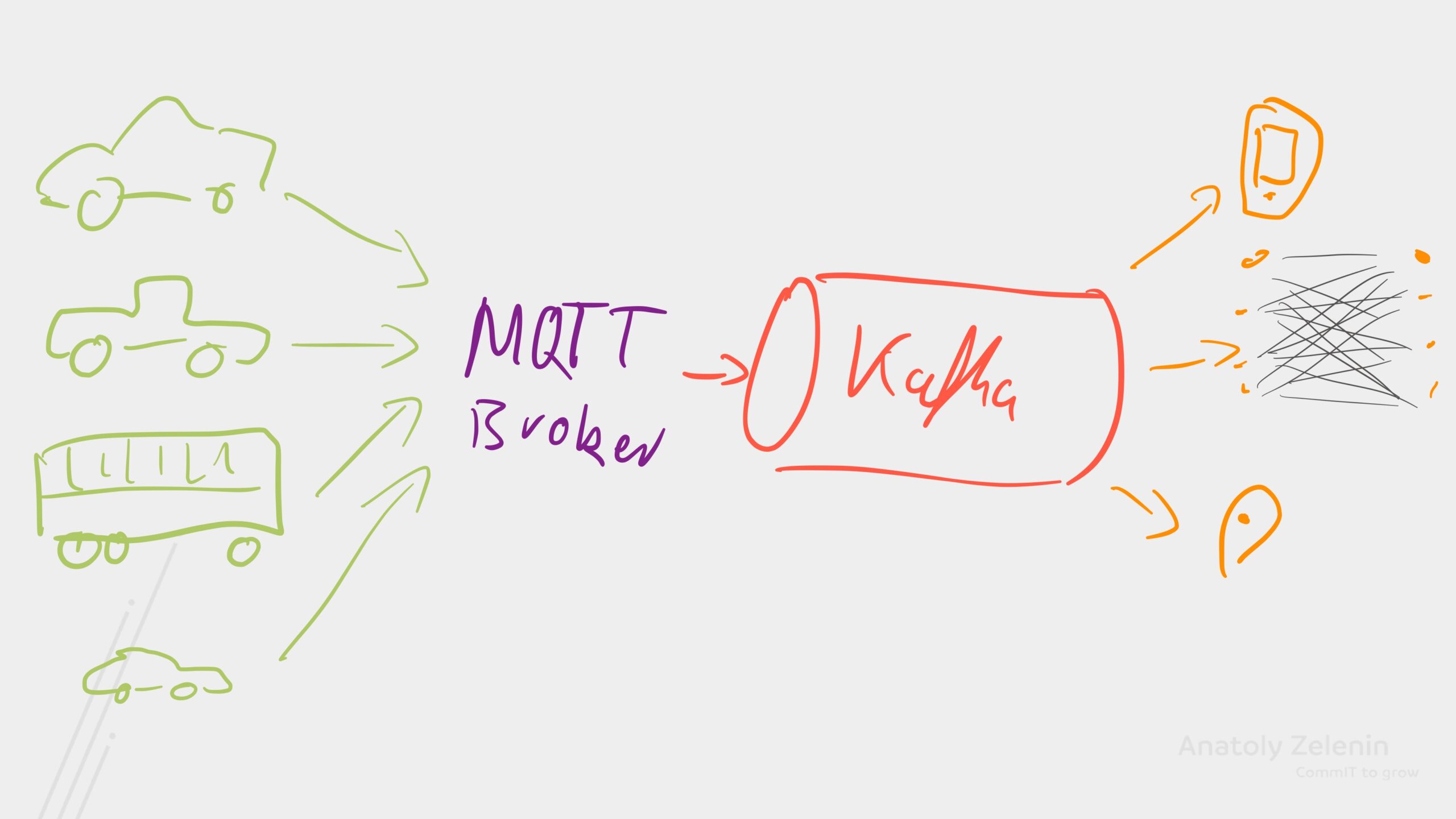
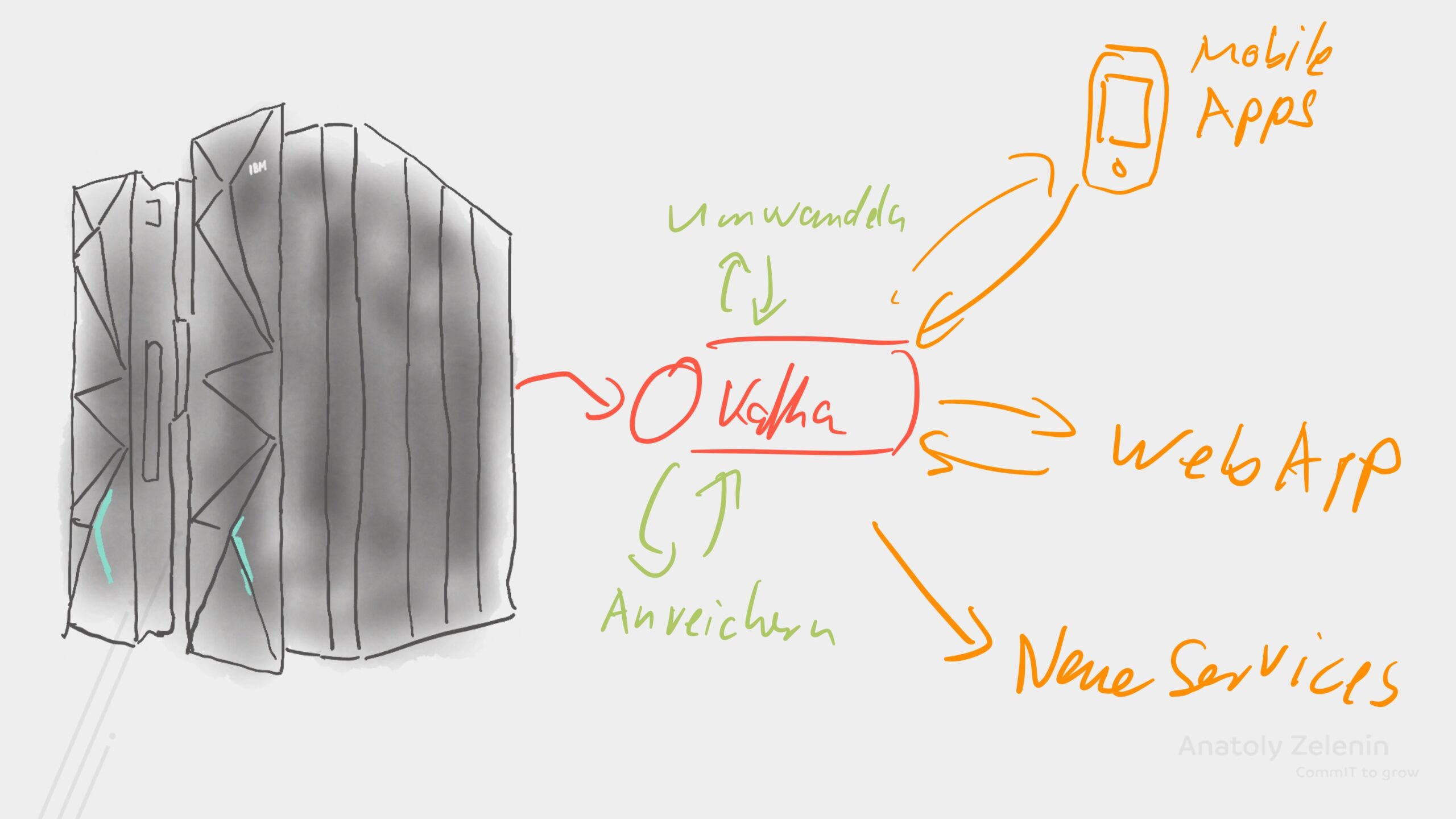
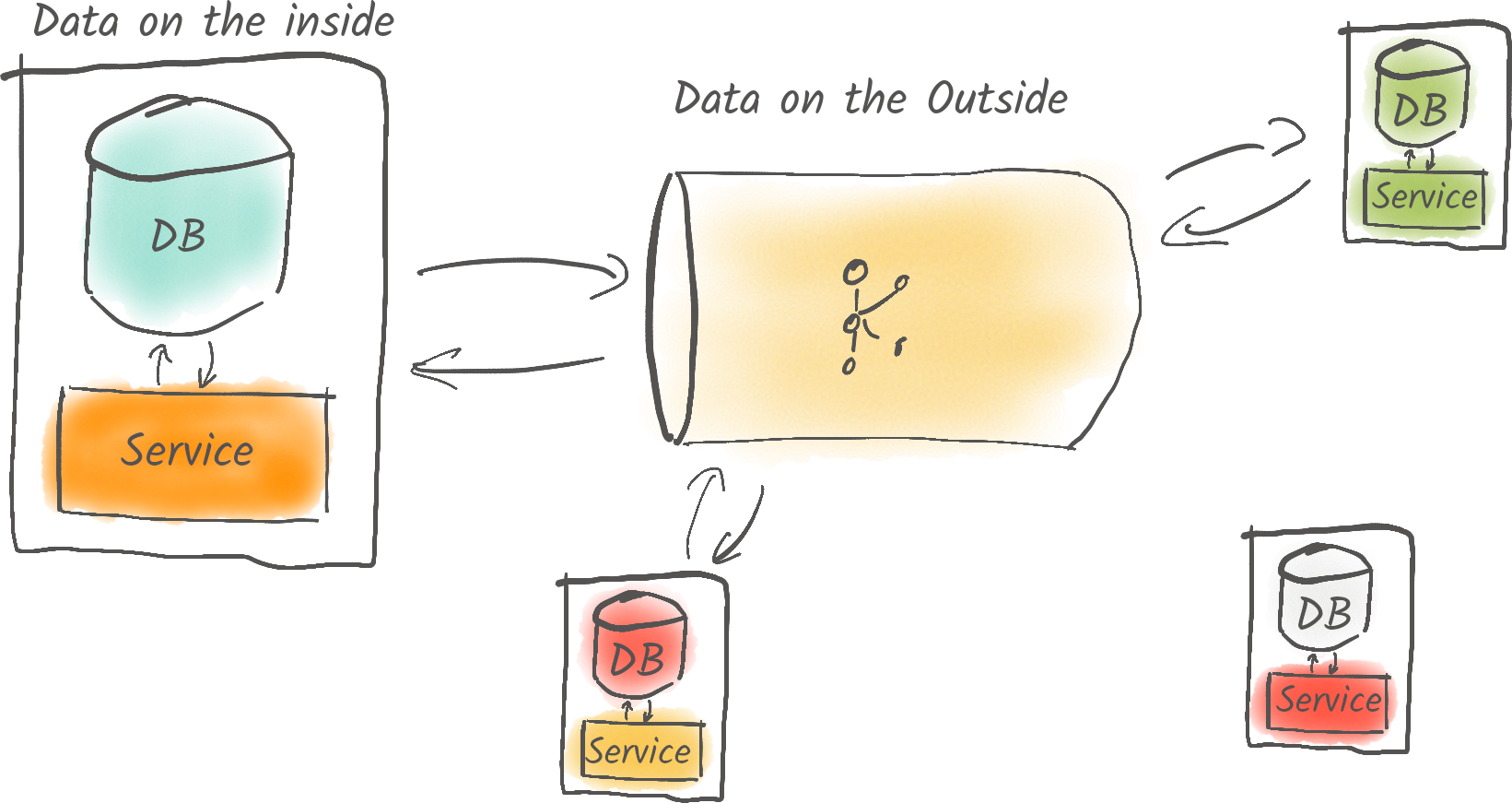
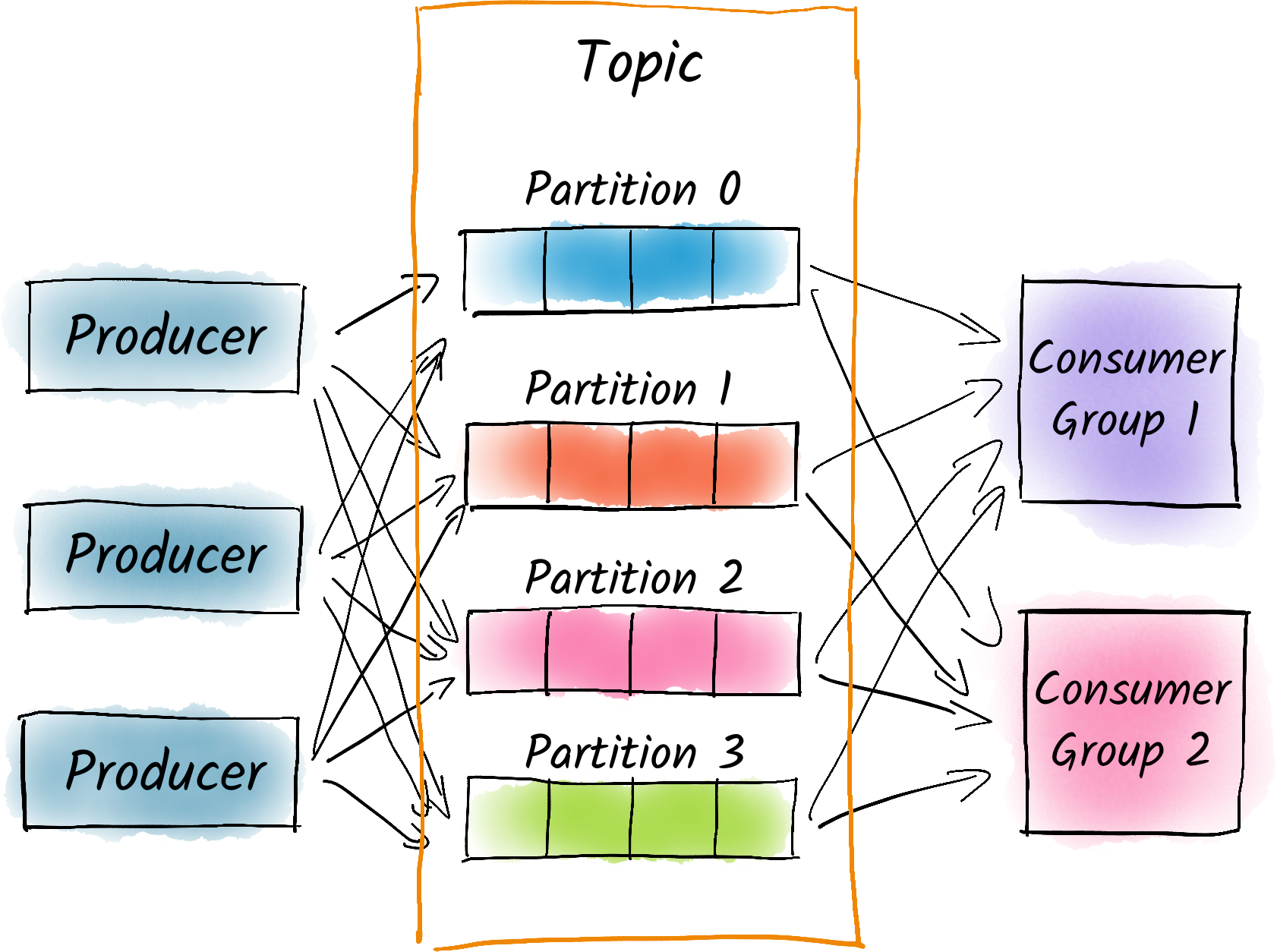
14.02.2024In diesem Post zeige ich dir, wie du mithilfe von Debezium Daten aus verschiedenen Datenbanken zuverlässig und nahezu in Echtzeit nach Kafka importieren kannst. Debezium ist ein Kafka Connect-Plugin, das sich an das interne Log jeder Datenbank anschließen kann, um Änderungen zu erfassen und in Kafka zu schreiben.